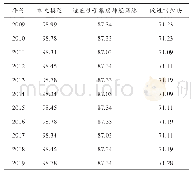
《表3 不同模型下的测试精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《SentiBERT:结合情感信息的预训练语言模型》
%
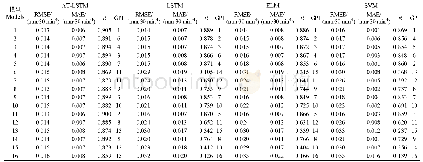
从图4可以看出,相较原BERT模型,本文方法在不同数量的训练数据集下均能取得较好的效果,特别在样本数量较少的情况下,BERT的3种训练方式差异较大,随着训练数据增多,本文的模型精度收敛更加迅速。最终,在全数据集下,3个模型的差距较小样本下已经不够明显,猜测足够的人工标注样本使得BERT推断出了一定的情感,补偿了加入的单词情感信息。
| 图表编号 | XD00151458300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 杨晨、宋晓宁、宋威 |
| 绘制单位 | 江南大学人工智能与计算机学院、江南大学人工智能与计算机学院、江南大学人工智能与计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}