《表3 文本数据主题识别结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
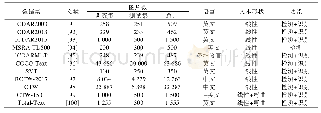
采用MG-LDA模型分别对由图像数据中抽取的文本和文本数据进行主题识别.使用Python语言实现MG-LDA模型,参照文献[16-17]给出的模型参数值,并通过实验调整,得到参数赋值为:全局主题分布的狄利克雷(Dirichlet)参数αgl=0.6,局部主题分布的狄利克雷参数αloc=0.6,全局单词分布的狄利克雷参数βgl=0.01,局部单词分布的狄利克雷参数βloc=0.001,αglmix=0.01,局部主题先验分布的非对称贝塔(Beta)参数αlocmix=0.50;先验分布的对称狄利克雷参数γ=0.01.全局主题数gl=18,局部主题数loc=6;窗口中相邻句子数T=3;迭代次数I=1 000.识别后筛选出的全局主题和局部主题中可做为舆情要素的词语如表3和表4.由表3和表4可见,由图像中识别的舆情要素可作为引发网络舆情的必要条件,但根据文本识别的主题词和图像识别的主题词有所不同.例如,在本研究针对性侵事件的分析中,发现图片等多媒体数据中提取的信息多和沉默、权利以及高官相关,比纯文本数据蕴含了更多的舆情要素,社会关注的焦点往往会在受害者或者事件中的强势群体,这就更加容易形成舆情[18].可见,综合分析图像和文本等多模态数据,可更加完善的获取舆情关联要素,这对于监控舆情演化趋势十分重要.
| 图表编号 | XD00124074500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.30 |
| 作者 | 刘润奇、贺兴时、南夷非、王博 |
| 绘制单位 | 西安工程大学理学院、西安工程大学理学院、西安交通大学智能网络与网络安全教育部重点实验室、西安交通大学智能网络与网络安全教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



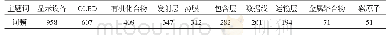

{kind=link}