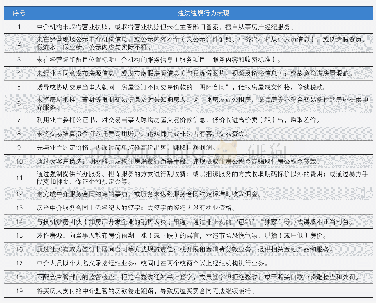
《表1 交通违法行为筛选的阈值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于K-Means聚类的交通违法行为与事故关联关系研究》
违法类型种类繁多,但有些类型在交通系统中出现频次不高或相对各个事故类型分布差异性不大,对于这些违法类型研究意义不大,应从原始数据中剔除,同时也有利于提高模型性能。筛选违法类型包括以下步骤:统计违法类型在违法数据中的次数—总计次数,选取违法类型次数的25%分位数作为阈值1(Φ1),筛选总计次数大于阈值1的违法类型;统计违法-事故对应矩阵中每种违法类型的次数—对应次数,选取违法类型次数的25%分位数作为阈值2(Φ2),在上一步筛选的基础上,进一步筛选对应次数大于阈值2的违法类型;计算上一步筛选出的每种违法类型相对事故类型的离散系数,选取离散系数的25%分位数作为阈值3(Φ3),在上一步筛选的基础上,进一步筛选离散系数大于阈值3的违法类型。通过以上三次阈值筛选,筛选出具有研究意义的违法类型,具体数值见表1。通过违法类型筛选,从接近300中违法行为中筛选出了54种有意义的违法类型数据。
| 图表编号 | XD00123083400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 王继博、杨蕾 |
| 绘制单位 | 中国交通通信信息中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}