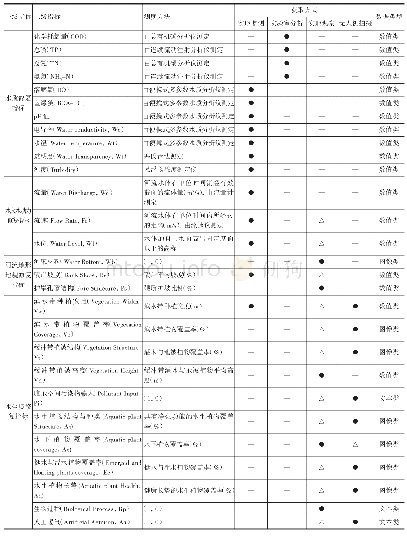
《表1 SparkSQl处理方式与关系型数据库数据获取时效比对》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《Hadoop环境下基于SparkSQL海量自动站数据查询统计初探》
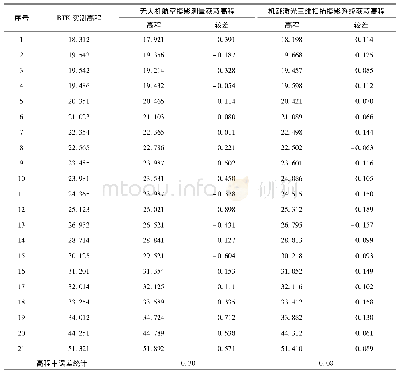
为了客观检验统计处理和查询时效,每次测试用例都使用的不同的站点和不同的时间跨度,将从关系型数据库的日统计值表进行查询的耗时与本文通过SparkSql的并行运算直接对流转合并的数据文件进行处理统计的耗时进行比对(表1)。可以看出,当站点个数少且时间跨度不超过1年时,两种模式的数据获取耗时相差不大,基本处于秒级别的处理响应时效;当站点数较多成类似几何级增长且时间序列跨度超过1年时,基于SparkSql的处理统计耗时就体现了其在性能和效率上的优势,耗时较关系型数据库缩减10倍甚至更多。
| 图表编号 | XD00104937700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 黄志、詹利群、任晓炜、李涛 |
| 绘制单位 | 广西区气象信息中心、广西区气象信息中心、广西区气象信息中心、广西区气象信息中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}