《表6 持续时长预测指标》
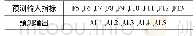 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
根据上述最大信息系数进行事故持续时长和影响因素相关性分析,选择前8个相关因素建立预测指标见表6。以最大信息系数筛选得到的因子作为预测模型输入,5种事故持续时长作为输出,分别利用支持向量机(Support Vector Machine,SVM),K最邻近(K-Nearest Neighbor,KNN),卡方自动交互检测(Chi-Squared Automatic Interaction Detection,CHAID),逻辑回归(Logistic Regression,LR),线性判别分析( (Linear Discriminant Analysis,LDA)建立事故持续时长预测模型,将事故数据集随机分成80%和20%用于训练和测试分析因子筛选后对预测模型准确度的影响,不同模型的准确度如图6所示。
| 图表编号 | XD0081923400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 樊梦琳、郑伟##教授 |
| 绘制单位 | 北京交通大学国家轨道交通安全评估研究中心、北京交通大学智能交通数据安全与隐私保护技术北京市重点实验室、北京交通大学国家轨道交通安全评估研究中心、北京交通大学智能交通数据安全与隐私保护技术北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}