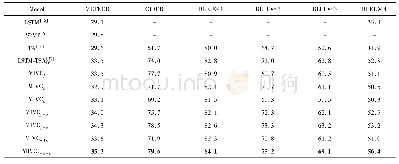
《表1 MIVC模型和其他流行的方法在MSVD数据集上的指标对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(%)
首先,为了评估视频不同语义特征和它们不同组合之间的有效性,在模型MIVC中采用6种不同的语义属性组合,同时串接vf,vc,vo作为视频最终的特征向量v输入到解码器中。其中“MIVCf”表示仅仅使用语义属性sf,“MIVCf+o”表示使用两个语义属性sf和so,其他四种模型遵守相同的标记,f,o,c分别表示sf,so和sc。表1展示了本文提出各种模型与目前流行方法在MSVD数据上的性能比较。可以看出:(1)本文所提出的模型“MIVCf+o+c”在6个评价指标上均取得了最好的实验结果。特别地,该模型在METEOR和CIDER指标上分别为35.3%和79.6%,是对比方法中效果最好的模型。(2)对于MIVC模型的六种变体,比如“MIVCf”、“MIVCf+o”和“MIVCf+o+c”,六个评价准则的分数值逐渐增大。这表明随着多模态语义属性的加入,模型的视觉表达能力变强,更加有利于视频描述语句的生成。也就是说MIVCf+o+c的性能优于MIVCf和MIVCf+o,这证明了学习到的多模式语义属性能够增强视频描述的性能。(3)即使只使用一种语义属性sf,“MIVCf”模型在METEOR和CIDER指标上也接近甚至优于LSTM-TSA[17],证明所提出MIVC基本框架的有效性。
| 图表编号 | XD0078283700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.10 |
| 作者 | 孙亮 |
| 绘制单位 | 中国科学技术大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |

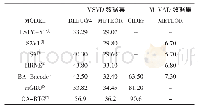



![表3 本文方法与文献[1,14,15]方法在筛选数据集上的评价指标对比](http://bookimg.mtoou.info/tubiao/gif/JSJY202008034_08200.gif)
{kind=link}