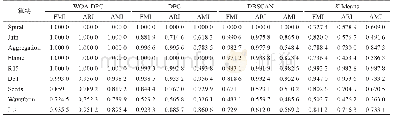
《表2 与其他算法比较结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
混淆矩阵的每一行代表预测值,每一列代表的是实际的类别。从混淆矩阵中我们可以看出系统对于区分每个类存在的一些问题和每个类识别的精确度和错误率。正确的预测结果都在对角线上,所以从混淆矩阵中可以很方便直观的看出哪里有错误[14]。由图7和8的右下角数据得知有数据增强的残差网络的识别率为90.2%,而没有数据增强的残差网络的识别率为84.7%。而且在每一个类中识别时,在没有使用数据增强的网络的识别率比较低,并且其中一部分类和其他类的识别率相差比较大。本文的算法也与其他的算法进行了比较,如表2所示。
| 图表编号 | XD0061600000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 吴睿曦、肖秦琨 |
| 绘制单位 | 西安工业大学(未央校区)、西安工业大学(未央校区) |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}