《表1 字符语义距离:一种基于字向量和LSTM的句子相似度计算方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
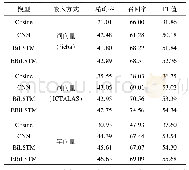
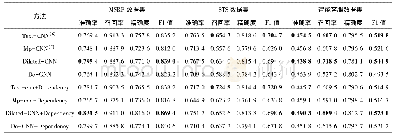
采用维基百科中文语料(zhwiki-20180120-pages-articles,1.42G),对该语料进行繁体转简体、去除数字、特殊符号、停用词等处理后,使用Word2Vec的Skip-gram模型进行训练得到字向量。为了对比不同粒度向量在模型上的效果,额外训练了词向量,分词工具使用jieba。字向量和词向量的维度均为400维,上下文窗口大小设置为5,词频最小值为5。从字向量训练结果中选择中心字“书”和“房”来计算语义距离最近10个字,结果如表1所示。另外,为了对比不同粒度向量效果,从词向量训练结果中选择中心字“图书”和“学生”来计算语义距离最近4个词语,结果如表2所示。
| 图表编号 | XD0028886500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.25 |
| 作者 | 何颖刚、王宇 |
| 绘制单位 | 集美大学诚毅学院、集美大学诚毅学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}