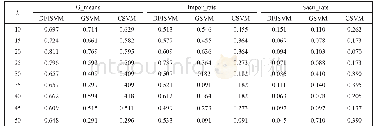
《表4 在6个数据集上实验指标的对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验结果如表4。由表4实验结果发现,在人工数据集和UCI数据集上,MR-RF-IS和Spark-RF-IS算法在测试精度和选择比上数值近似相同,是因为MR-RF-IS和Spark-RF-IS在算法结构和运行逻辑上基本秉承同种思想,算法在执行样例选择时所选择的样例子集也是大致相同的,选择出的样例子集重要程度也近乎相似;但两种算法的在不同的平台上所运行的时间有着很大的差距,造成这种差距的主要原因是在Map Reduce和Spark大数据处理平台上对数据的处理采取截然不同的策略。基于随机森林的大数据样例选择在大数据计算平台上算法主要在I/O操作和中间数据传输上消耗过多时间,其运行时间T可以分为文件读取时间Tread、中间数据传输时间Ttran、中间数据排序时间Tsort和文件输出时间Twrite;其中,文件读取时间Tread受文件读取速度和文件的影响,文件输出时间Twrite受文件输出速度和文件数量的影响。在Map Reduce和Spark平台上,文件的输入输出速度和数据的数量的差异主要是受到不同平台的运行机制和读写方法影响,所以只对中间数据传输时间Ttran和中间数据排序时间Tsort造成的影响进行分析。
| 图表编号 | XD00201766800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.10 |
| 作者 | 周翔、翟俊海、黄雅婕、申瑞彩、侯璎真 |
| 绘制单位 | 河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室(河北大学)、河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室(河北大学)、河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室(河北大学)、河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室(河北大学)、河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室(河北大学) |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}