《表7 两种算法在Gauss2数据集上实验结果的对比(单位:s)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《MapReduce和Spark两种框架下的大数据极限学习机比较研究》
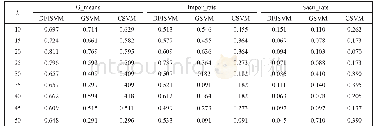
该实验是在拥有1个主节点和7个从节点的云计算平台上进行的,在云计算平台上搭建了Hadoop和Spark两个运行环境,云计算平台节点的基本配置信息和功能规划如表2和表3所示,主机的基本配置如表4所示,实验所需数据集的基本信息如表5所示.实验将从训练数据维度、训练数据规模和隐层节点个数三个方面作为实验参数对含有10、20、30、50、100个隐含层节点的ELM网络模型,比较了基于M apReduce和Spark的并行ELM算法的执行时间,实验结果列于表6~表10中.对实验结果进行分析,得出了结论:基于Spark的ELM算法的效率远远高于基于M apReduce的效率,随着隐含层节点个数逐渐增多,Spark平台的优势愈加明显.在下一节中,我们将从理论层面分析产生该现象的原因.
| 图表编号 | XD00175973500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 宋丹丹、翟俊海、李艳、齐家兴 |
| 绘制单位 | 河北大学数学与信息科学学院、河北大学数学与信息科学学院、河北大学河北省机器学习与计算智能重点实验室、河北大学数学与信息科学学院、河北大学河北省机器学习与计算智能重点实验室、河北大学数学与信息科学学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}