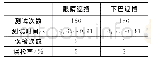
《表1 测试结果:基于CNN网络的带遮挡车牌识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
通过形态学算法构建的样本库主要分为汉字、字母和数字三大类,其中每一个字符通过不同形态、旋转角度、遮挡情况等共构造出10240个样本,随机取其90%作为训练集,其余为测试集。训练框架为TensorFlow1.4,将训练集转存为tfrecord类型以节约内存、统一格式并提高计算效率,通过CNN对样本进行训练与测试,最后实现对车牌的识别。实验设置卷积层池化层各两层,最终通过两层全连接层实现特征输出。具体参数设置:学习率为0.8,学习率的衰减率为0.99,损失函数系数为0.001,每一批次训练128张图片,训练至3200步时趋于收敛,精度为99.978%。同时使用上述网络训练无遮挡的字符样本,每类6542张图片,并对比不同样本库对识别效果的影响,如表1所示。
| 图表编号 | XD00200146300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.18 |
| 作者 | 刘靖钰、刘德儿、杨鹏、陈增辉、邹纪伟、冀炜臻 |
| 绘制单位 | 江西理工大学建筑与测绘工程学院、江西理工大学建筑与测绘工程学院、江西理工大学建筑与测绘工程学院、江西理工大学建筑与测绘工程学院、江西理工大学建筑与测绘工程学院、江西理工大学建筑与测绘工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}