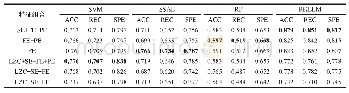
《表2 两种模型的分类性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
我们采用准确率(accuracy,ACC)、查准率(precision,PREC)、受试者工作特征(receiver operating characteristic,ROC)曲线下的面积(area under curve,AUC)(ROC AUC)、PR(precision-recall)曲线下的面积(PR AUC)、Kappa系数(Cohen’s Kappa)、F1分数(F1 score,F1)来衡量模型的分类性能。准确率常用来判断分类器分类结果的好坏。受试者工作特征曲线下的面积、PR曲线下的面积常用来衡量分类器的泛化能力。Kappa系数用于一致性检验,也可以用于衡量分类精度。查准率是针对模型预测结果而言的,表示的是预测为正的样例中真正的正样例的比率。F1分数是统计学中用来衡量二分类模型精确度的一种指标,同时兼顾了分类模型的精确率和召回率。由于训练数据中存在大量的非协同非拮抗药物组合(协同值在0左右),因此,选择一个适当的阈值来将预测的协同作用值进行二值化是很重要的。我们将二分类阈值设置为30,协同作用值高于30的药物组合被认为是正类,低于30的药物组合被认为是拮抗的和低协同的,这点与DeepSynergy模型相同。表2展示了两种模型在测试集上的分类性能对比。
| 图表编号 | XD00154977000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.25 |
| 作者 | 陈希、秦玉芳、陈明、张重阳 |
| 绘制单位 | 上海海洋大学信息学院、农业农村部渔业信息重点实验室、上海海洋大学信息学院、农业农村部渔业信息重点实验室、上海海洋大学信息学院、农业农村部渔业信息重点实验室、上海海洋大学信息学院、农业农村部渔业信息重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}