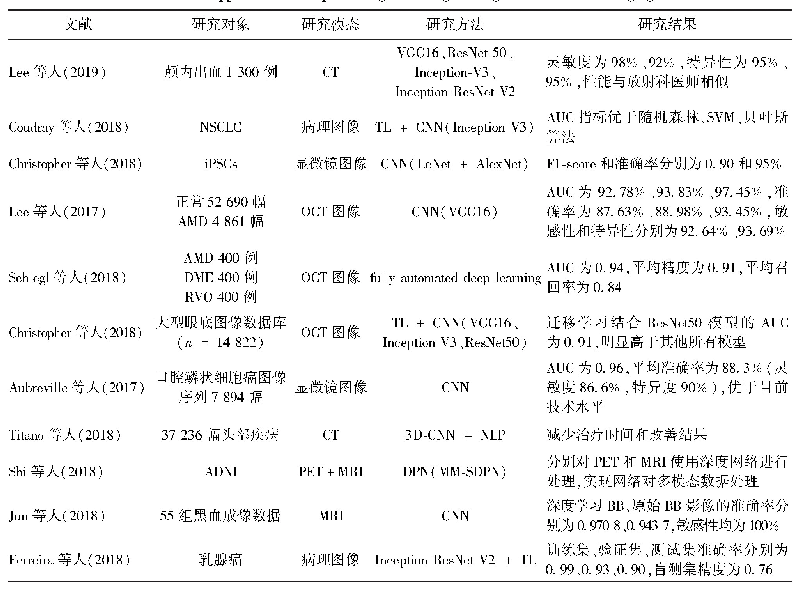
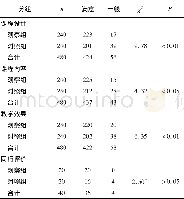
《表3 训练结果(%):1种应用于医学影像诊断报告的智能纠错方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了让模型对错误更加敏感,构建的语序数据集所采用的正负样本比例为1:4,而词语替换数据集中所采用的正负样本比例为1:3。表3中显示,通过语序训练集训练得到的模型Model1对语序的正误识别的准确率达到了99%以上,而通过词语搭配训练集训练得到模型Model2对词语替换句子正误识别的准确率达到了98%以上。本训练集、测试集和验证集中所采用的负样本比例较高,如果换成正负样本比例1:1的数据集,准确率会有一定的降低。
| 图表编号 | XD00113464000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 李文杰、王小冬、简刚、唐武斌 |
| 绘制单位 | 宁波市科技园区明天医网科技有限公司、宁波市科技园区明天医网科技有限公司、宁波市科技园区明天医网科技有限公司、宁波市科技园区明天医网科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |
{kind=link}