《表2 仿真初始条件:基于深度强化学习的智能PID控制方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
选用深度强化学习算法中的DDPG算法训练深度神经网络,目标为控制飞行器俯仰通道过载跟踪外部过载指令。深度强化学习是一种弱模型依赖的控制器设计方法,当飞行器的模型发生摄动时,由深度强化学习设计的控制器仍能实现飞行器精确的姿态控制。在仿真中,首先强化学习算法与外部环境进行交互,得到满足要求的控制器,再将飞行器的气动参数加上不同程度的摄动,验证当飞行器的模型发生变化时,强化学习方法设计的控制器仍然有效。本文同时设计了LQR控制器用以比较分析,LQR控制器参数为K1=-5.38,K2=-4.1。飞行器俯仰通道的气动参数如表1所示,仿真初始条件如表2所示。
| 图表编号 | XD00110337800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 甄岩、郝明瑞 |
| 绘制单位 | 复杂系统控制与智能协同技术重点实验室、复杂系统控制与智能协同技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
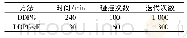




{kind=link}