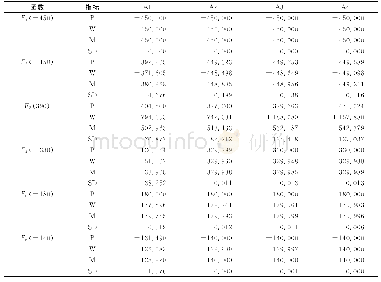
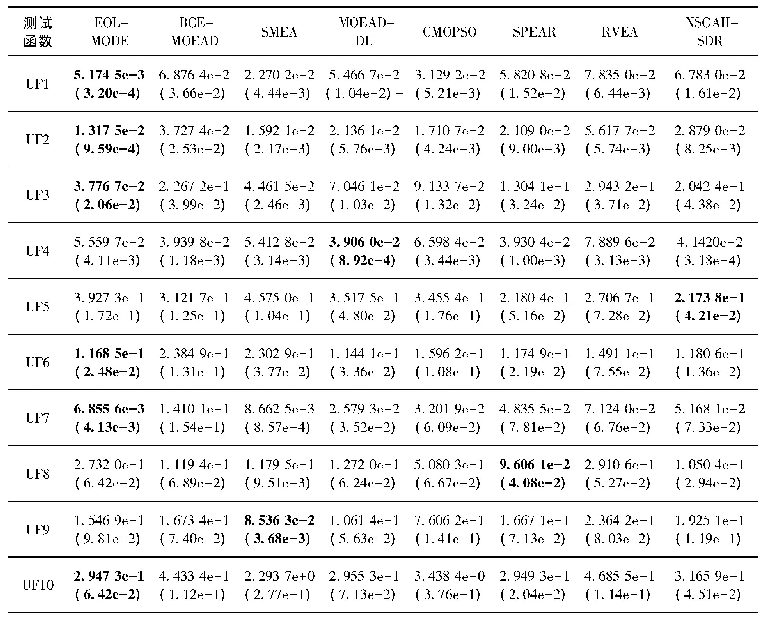
《表8 不同算法在6个测试函数上的对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
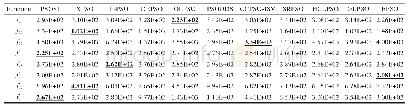
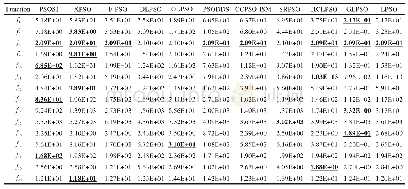
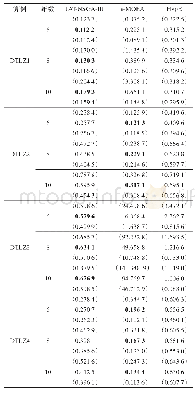
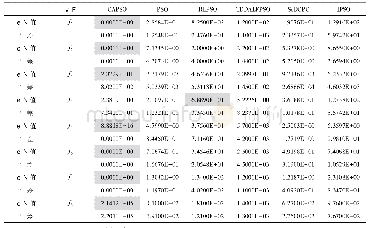
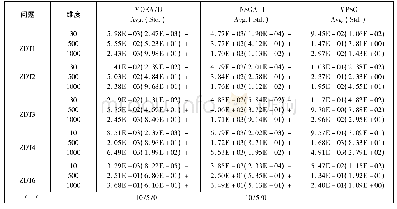
综上所述,本文针对ETLBO算法进行优化,通过提出一种奖励机制,在“学”阶段学生有更大的概率向优秀个体学习,从而加快收敛速度.根据该机制提出了相应的ETLBO-reward算法,并提出一种简单的自适应精英个数RETLBO-reward算法.实验部分应用ETLBO-reward算法和RETLBO-reward算法求解连续非线性函数F1~F6.实验结果表明,ETLBO-reward算法在整体上优于ETLBO算法,并且RETLBO-reward算法在省略了确定精英个数过程的同时保证了较好的求解效率.
| 图表编号 | XD00106870800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.26 |
| 作者 | 吴云鹏、崔佳旭、张永刚 |
| 绘制单位 | 吉林大学计算机科学与技术学院符号计算与知识工程教育部重点实验室、吉林大学计算机科学与技术学院符号计算与知识工程教育部重点实验室、吉林大学计算机科学与技术学院符号计算与知识工程教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
{kind=link}