《表2 τ=0.7时HC1的实例数和分类精度 (German信用数据)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于模糊粗糙集实例选择的混合算法在信用评分中的应用》
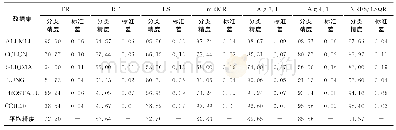
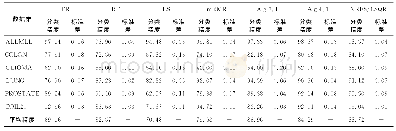
图2和图3是根据密度聚类算法[22]绘制的German和Australian数据集的MDS图.MDS图表明,German的数据分布比较分散,而Australian数据相对比较集中.从表2~表7可以看出,固定τ值,German信用数据的约简结果随着α的改变而剧烈变化,而Australian信用数据的约简结果却对比变化不大.再观察表8和表9,随着α值的变化,2个数据集的约简结果变化趋势相似,约简结果完全由颗粒度系数决定.上述现象说明,由于German数据集分散的特性,HC1通过固定门限剔除了更多的孤立和不一致实例.而HC2通过动态的正域探索数据结构,比HC1剔除了更多的Australian数据集中的噪声实例,但却用更少的实例获得了更好的分类精度.从实验结果来看,HC1更适合分散型的数据集,而HC2对相对集中的数据集更加有效.
| 图表编号 | XD0052004600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 刘占峰、潘甦 |
| 绘制单位 | 南京邮电大学江苏省通信与网络技术工程研究中心、南京邮电大学江苏省通信与网络技术工程研究中心 |
| 更多格式 | 高清、无水印(增值服务) |
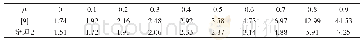



{kind=link}