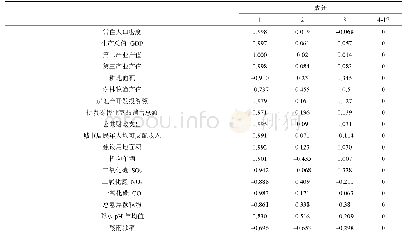
《表1 SPSS输出的模型拟合数据》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由图4可知,自相关和偏自相关基本都收敛在置信区间内,且都属于截尾的属性,因此可对原始序列建立ARIMA(p,0,q)模型。p值和q值的确定也有多种方法,主要包括以下几种:(1)观察法。直接观察,如果自相关图在q+1阶突然截断趋近于0,则在q处截尾。同理,偏自相关图在p+1处截断趋近于0,则在p处截尾,二者结合判断。(2)参数检验。利用数理统计检验高阶模型新增加的参数是否近似为零,判断检验模型残差的相关特性等。(3)信息准则。确定一个与模型阶数有关的准则,如赤池信息准则(Akaike information criterion,AIC)、贝叶斯信息准则(Bayesian information criterion,BIC)等,既考虑拟合效果接近程度,又考虑参数个数[11-12]。在实际应用中可多种方法综合应用,本文采用观察法判断。从图4可以看出,虽然2幅图中截尾属性的地方不止一处,但自相关图中q=3开始突然截尾,偏自相关图中p=2开始突然截尾,故p=2,q=3。依次点击“分析”—“预测”—“创建模型”,将“因变量”设为“血氧”,“自变量”设为“日期”,“方法”设为ARIMA,“条件”设为“p=2,d=0,q=3”,并在“统计量”选项卡中,“拟合变量”选择“平稳的R方”和“R方”,“比较模拟”中选择“拟合优度”,“个别模型统计中”选择“参数估计”,SPSS输出的分析结果见表1。
| 图表编号 | XD0045734700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.15 |
| 作者 | 向逾、潘克新、徐太祥、姚明 |
| 绘制单位 | 重庆市巴南区人民医院总务科、陆军特色医学中心设备科、陆军特色医学中心设备科、重庆市巴南区人民医院儿科 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}