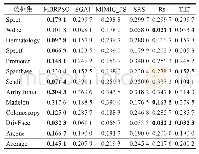
《表4 各欠采样方法在SVM上的F-Measure (G-Mean) 表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
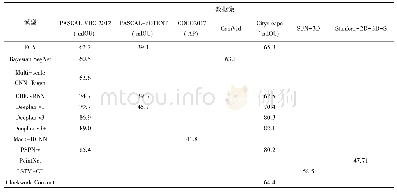
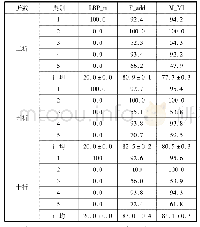
表4和表5可以看到应用NearMiss-2后的CCNM算法与其它算法在10个数据集上F-Measure和G-Mean的表现.随机欠采样是最简单的方法,但如上表展示一样,由于随机性会去除大量的有用信息,R-andom算法无论在F-Measure还是G-Mean上都有着较低的分数.但值得注意的是,随机欠采样在le-tter、wine和balance数据集上有着尚可的表现,原因是这两个数据集是多类别的,将稀有类别作为少数类而其他类别作为多数类时,随机欠采样后的多数类样本在各个类别的分布可能是比较均匀的,利于后面的分类学习.CCNM算法首先利用聚类将多数类样本进行归类,再利用NearMiss-2对各个簇周围少数类样本个数进行分析,这样选出的多数类样本不仅具有更丰富的信息,在样本空间分布上也能围绕着少数类.因此,CCNM在不平衡数据分类任务中有更好的性能,尤其在不平衡度较高的yeast和glass数据集上提升明显,聚类在此处起到了很明显的去噪声的作用,同时保留了信息量高的多数类.
| 图表编号 | XD0045034200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 魏力、张育平 |
| 绘制单位 | 南京航空航天大学计算机科学与技术学院、南京航空航天大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}