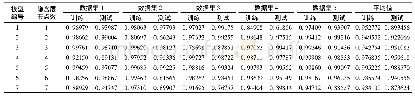
《表4 T2模型的训练与预测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:(1)每个表格中的4个数值分别为均值、标准差、最小值、最大值,准确率的单位为百分比。(2)拟合样本是均衡化处理后的训练样本,实际样本是未均衡化的初始训练样本。(3)违约训练样本34个,拟合样本8个。
下文以T2模型为例,对模型的分类效果进行分析(3)。随机抽取8个违约样本作为测试样本,其余34个违约样本作为训练样本。采用训练样本对T2模型的参数进行拟合估计后,使用拟合得到的T2模型对测试样本的预测效果进行分析。针对AD-Logistic模型和RU-Logistic模型,均进行100次重采样,各产生100组均衡化后的训练样本,再分别使用Logistic分类器进行100次拟合(AD-Logistic模型采用ADASYN算法进行100次过采样,RU-Logistic模型则重复100次有放回的随机欠采样)。表4为应用AD-Logistic模型和RU-Logistic模型对T2模型进行100次拟合和预测的结果。
| 图表编号 | XD0031384000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 张永东 |
| 绘制单位 | 广州农村商业银行 |
| 更多格式 | 高清、无水印(增值服务) |
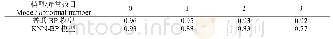




{kind=link}