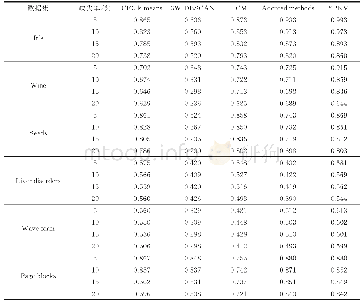
《表2 对比算法在Subset Accuracy上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于每个数据集,每次实验随机抽取80%的样本作为训练集,剩余的20%作为测试集,观察每种多标记算法在不同数据集上的性能表现,重复实验10次取平均值作为实验结果,最终的实验结果如表2-表5所示,粗体表示最优的算法结果,↑表示该评价指标的值越大算法性能越优。
| 图表编号 | XD00212758200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.15 |
| 作者 | 秦梦莹、秦锋 |
| 绘制单位 | 安徽工业大学计算机科学与技术学院、安徽工业大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}