《表1 超高层钢结构建筑:基于文本聚类的主题发现方法研究综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
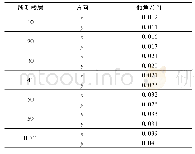
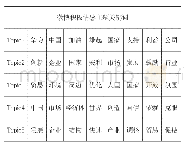
聚类分析又称群分析,是一种重要的统计分析方法,目的是把具有相同特征的元素划分到一块,常常被用于数据挖掘与文本分析中,主题聚类或称为文本聚类[6],即挖掘文本的相似性,基本思想是将语料集中预处理之后的文本术语向量化,抽象成可计算的元素,之后依据元素之间的距离或相似性进行归类且聚成簇,进而将每个簇的主题及主题关系抽取出来,形成具有不同主题的簇或类别,从而使用户能快速掌握目标文本的核心主题信息。空间表示、距离计算和算法的选取是聚类技术的三大关键要素[7],其中,距离计算是类别划分的基本依据,有基于语境、语法和词法等的计算方法[8],而聚类算法[9]一般分为划分法、层次法和基于网格、密度和模型的方法,其特点见表1。本文就结合近几年国内外的相关文献,针对有关文本聚类方法的主题发现研究成果来梳理主题发现方法的研究脉络,旨在为今后学者开展该领域的相关研究提供参考和借鉴。
| 图表编号 | XD00204837400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.15 |
| 作者 | 李璐萍、赵小兵 |
| 绘制单位 | 中央民族大学信息工程学院、中央民族大学国家语言资源监测与研究少数民族语言中心、中央民族大学信息工程学院、中央民族大学国家语言资源监测与研究少数民族语言中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}