《表4 不同方法在中文单语数据上的实验对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
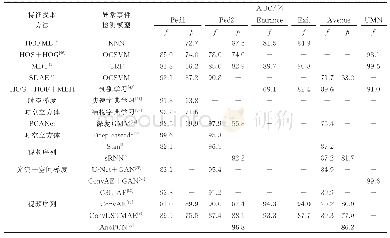
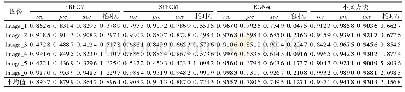
在中文单语数据上和其他方法进行比较,由于之前方法都是在统计机器翻译生成的译文上提取特征进行实验,本文所使用的数据集中的译文为神经机器翻译生成的译文,译文质量相对较高,所以基于统计特征的方法性能有所下降。我们所提出的方法在相同数据集上达到了最好的效果。实验结果具体参见以下示例(表4)。
| 图表编号 | XD00193207500 严禁用于非法目的 |
|---|---|
| 绘制时间 | |
| 作者 | 田科、张家俊 |
| 绘制单位 | 中国科学院自动化研究所模式识别国家重点实验室、中国科学院大学人工智能学院、中国科学院自动化研究所模式识别国家重点实验室、中国科学院大学人工智能学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}