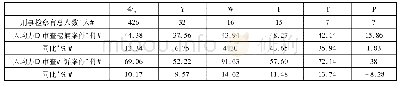
《表2 法官办案工作事项统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
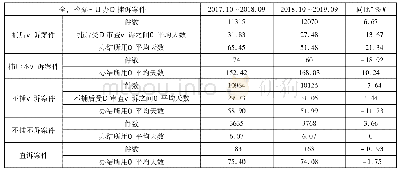
在测算模型中,个案权重因素对法官工作量的影响强弱程度表现为权值,为每个权重因素赋予相应的合理权值,方能计算出个案工作量进而测算工作总量。关于权值算法,一种较为直接的思路是对测算样本中所有具备该权重因素的案件,法官每个办案流程节点的工作事项进行统计,并对各项工作平均耗时进行估算(计为t1、t2……t10)(参见表2) ,求出审理该权重因素案件的平均耗时t=t1+t2+……+t10(可能有缺项,缺项赋值0)。同法求出所有取样案件平均审理耗时T=T1+T2+……+T10,最终通过平均审理耗时的比较得出该类案件权重W,即W=t/T。该计算思路缺陷在于,其依赖于分项统计的方式得出所有取样案件及某类案件的总平均耗时,然而并非所有工作事项的平均耗时均可准确统计,诸如庭审、调解、合议等工作事项耗费时间依据视频光盘和相关笔录,尚可得到较准确的统计数据,但如庭前准备、阅卷、调查核证、文书制作等事项耗费的时间,目前并无明确统计依据,往往只能根据法官事后记忆估算,其准确性难以保证。另一方面,从统计学角度看,参与统计的事项越多,分项误差累计后的总体误差则会越大,从而使该方法测算出的数值可能较大程度上偏离真实结果。
| 图表编号 | XD0018374500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.09.01 |
| 作者 | 吴涛、江明 |
| 绘制单位 | 中国浦东干部学院、安徽省芜湖市中级人民法院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}