《表4 Pfam软件预测到的lncRNAs》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
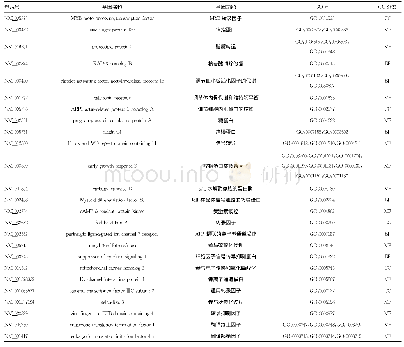
Pfam是一个大型蛋白结构域家族的数据库,每个蛋白家族都由多个序列比对和隐马尔可夫模型(hidden markov models,HMMs)所体现,将转录本各个编码框上的蛋白序列与Pfam数据库做hmmscan同源搜索,能比对上的转录本即为具有某个蛋白结构域的转录本,被认为具有编码能力,无比对结果的转录本则被认为是潜在的lncRNA(Finn et al.,2016)。当把全部转录本全长为基础数据导入时,Pfam软件预测到lncRNAs有24 504个基因片段(表4),其中最短的为280 nt,最长为10 756 nt。长度大都介于280~4 000 nt范围,这个范围的lncRNAs占到总数得97.593%;超过4 000 nt的很少,总共只有590个,占总数的2.407%。
| 图表编号 | XD00152933200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.14 |
| 作者 | 张宏意、卢昌华、何梦玲、严寒静 |
| 绘制单位 | 广东药科大学中药学院、广东药科大学中药学院、广东药科大学中药学院、广东药科大学中药学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}