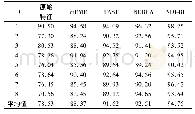
《表4 SVM分类器实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(2)实际数据集实验结果:本文使用KNN、SVM和RF分类器对原始数据集和经过采样之后的平衡数据集进行分类,实验结果见表3、表4和表5,其中F-value、G-mean和AUC取得最优值的数据用黑色粗体表示。对于每个数据集中的每个评价指标通过得分制来对各种算法进行排序,分值设置为1到6,其中性能最好的算法得6分,最差的得1分。针对未经过采样和五种过采样算法,对于每个数据集中的三种评价指标的平均得分再取均值,可以得到每种算法的最终平均得分。通过对比实验结果可以得出如下结论:(1)在相同的数据集中,使用RF分类器可以获得优于KNN和SVM分类器的分类效果,这是因为RF分类器将多个单一的弱分类器集合成一个强分类器,并且由于“随机性”的引入,使得RF分类器不易过拟合,同时具有较强的抗噪声能力。(2)相比于只对原始数据集使用KNN、SVM和RF分类器进行分类,使用SMOTE、Borderline-SMOTE、ADASYN、K-means SMOTE和DB-MCSMOTE过采样算法可以不同程度地提高分类器对数据集的分类性能。并且相比于SMOTE等传统过采样算法,使用DB-MCSMOTE算法可更大幅度提升分类器的分类性能,即DB-MCSMOTE算法可以获得最高的最终平均得分。因此DB-MCSMOTE算法不仅可以提高KNN等单一分类器的性能,同时也可以提升RF集成分类器对不平衡数据集的分类效果。(3)在Pima、Segment、Vehicle、Yeast1和Yeast-02579五个数据集中,使用DB-MCSMOTE算法可以同时取得最优的F-value值、G-mean值和AUC值,这是因为上述实际数据集不仅存在类间不平衡,并且在少数类类内也存在样本分布的不均衡,SMOTE等传统过采样算法未考虑少数类类内样本的分布情况。(4)在所有数据集中,使用DB-MCSMOTE算法在Yeast-02579数据集上取得的F-value值和G-mean值相比于SMOTE等算法的提升幅度最大,这是因为Yeast-02579数据集的不平衡度最高,需要合成更多新少数类样本,SMOTE等算法合成的新样本之间高度相似,而DB-MCSMOTE算法合成具有多样性的新少数类样本,可以为分类器提供更多的分类信息。以上结果总体来看,本文提出的DB-MCSMOTE过采样算法可以有效提升分类器对少数类样本和整体数据集的分类性能。
| 图表编号 | XD00150178100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.15 |
| 作者 | 王亮、冶继民 |
| 绘制单位 | 西安电子科技大学数学与统计学院、西安电子科技大学数学与统计学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}