《表4 PANDA 2018 Challenge1数据集PCA-20处理后方差(×104)表(汉明重量不同)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
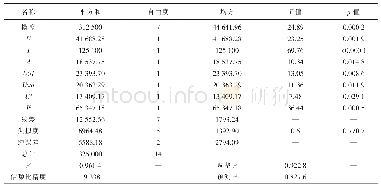
由表2和表3可知,在大部分情况下,经过预处理后的特征值的类内方差(对角线上的元素)明显小于类间方差(同行或同列其他数据)。PANDA 2018Challenge1数据采集自AT89S52单片机实现的AES算法,其能量数据的表现特征符合汉明重量模型,在实际的实验过程中,相同汉明重量的几类标签分类时,容易出现分类错误的情况。在表3中,大部分标签的类间方差也同样小于类内方差。也就是说,经过特征提取后,能量数据已经进行了可区分的分类。特别注意的是,在标签为13和131时,类内方差大于部分类间方差,此时,即为特征提取算法提取的特征不明显,难以区分标签为13和131的分类。为了更加直观的对比预处理效果,如表4和表5所示,将使用PCA-20和LDA-20算法进行处理后的数据方差如下,由表中数据可知,在汉明重量不同的9类标签中,也出现了大量类内方差大于类间方差的情况,密钥区分的难度将大大提高。
| 图表编号 | XD00146211200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 袁庆军、王安、王永娟、王涛 |
| 绘制单位 | 战略支援部队信息工程大学、河南省网络密码技术重点实验室、北京理工大学计算机学院、战略支援部队信息工程大学、河南省网络密码技术重点实验室、战略支援部队信息工程大学、河南省网络密码技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}