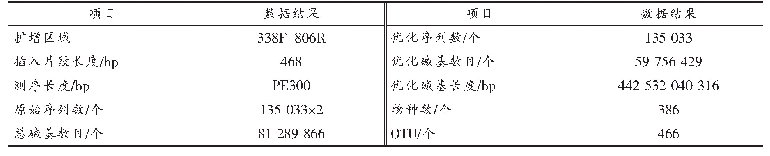
《表1 不同组织样品高通量测序数据评估统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于RNA-seq技术的江鳕不同组织转录组比较分析》
Q30:质量值≥30的碱基所占百分比
经过测序质量控制,共得到20.78 Gb的clean data,过滤后的碱基分布比较稳定,平均GC含量为53.16%,各组织样品Q30碱基百分比均不小于87.91%(表1)。将过滤后的reads片段进行聚类及拼接组装,共得到175 804条转录本(transcript)和106 084条unigenes,transcript与unigenes的N50(重叠群序列累加后长度超过转录组总长度一半时的重叠群序列长度)分别为2 285和1 254,组装完整性较高(图1)。其中长度在200~300 bp之间的unigenes数量最多,为42 058条,约占总unigenes数量的39.65%;长度>2 000 bp的数量最少,有7 975条,约占总数的7.52%。Transcript长度为200~300bp的数量最多,有48 087条,占总体的27.35%;长度为1 000~2 000 bp的数量最少,为29 251条,占总数的16.64%;长度300~500 bp、500~1 000 bp和>2000 bp的占比数量大致相当,分别为19.95%、18.02%和18.04%。这些Transcript和unigenes的组装为下一步进行功能注释和表达量研究提供了基础信息。
| 图表编号 | XD00121578600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.25 |
| 作者 | 杨天燕、蒋艳琳、韩志强、孟玮 |
| 绘制单位 | 浙江海洋大学水产学院、浙江海洋大学水产学院、浙江海洋大学水产学院、浙江省海洋水产研究所、浙江省海洋渔业资源可持续利用技术研究重点实验室、农业部重点渔场渔业资源科学观测实验站 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}