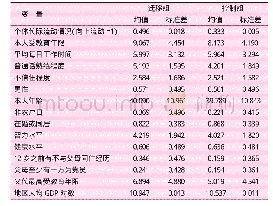
《表1 主要变量的描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
样本筛选的处理过程为:(1)利用个人代码对成人库与家庭关系库进行匹配,并删除父子年龄差距小于14岁的样本;(2)将样本集中于16~60岁的劳动人口,剔除仍在学个体;(3)剔除被解释变量缺失即子代和父代的职业得分信息缺失的个体;(4)剔除核心解释变量和控制变量缺失的个体,最终样本量为10 749个。相关变量描述性统计如表1所示。
| 图表编号 | XD0084844800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 宋旭光、何佳佳 |
| 绘制单位 | 北京师范大学统计学院、北京师范大学统计学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}