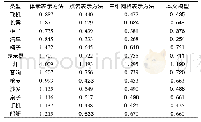
《表3 与其他模型的比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
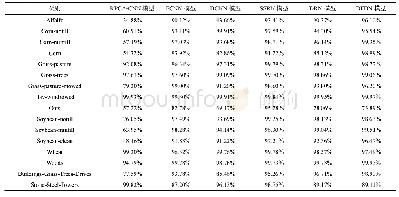
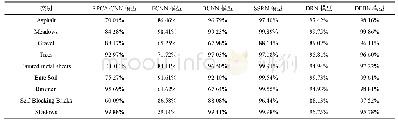
表3给出了本文模型与其他AMR解析模型的性能比较。需要注意的是,LDC2016E25和LDC2017T10是完全相同的数据集,并且采用完全一致的数据划分。而LDC2015E86与前两个数据集的开发和测试集是一样的,但是训练集大小只有它们的一半左右,由于该数据集仅对2015年AMR解析评估比赛的参与者开放,所以本文无法使用该数据集。从表3的结果中可以看出,在数据集同样是LDC2017T10的情况下,本文的“+句法+语义角色”的模型结果为69.4,优于Noord等基于字符的seq2seq模型[9]结果64.0。由于本文未使用Noord等的100k伪语料来扩充数据集,所以无法与其71.0的模型结果进行比较。当然,对于Foland等[24]、Guo等[21]和Lyu等[25]的非seq2seq模型也不进行比较。
| 图表编号 | XD0070612600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 葛东来、李军辉、朱慕华、李寿山、周国栋 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、阿里巴巴集团、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}