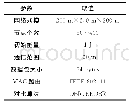
《表1 CaffeNet优化前后网络参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先,网络中的crop_size为227×227。在Caffe的训练过程中,训练和验证同时进行。test_iter值设置为260代表每1000次迭代计算一次误差,batch_size设置为16,即每次迭代的图像数是batch_size×crop_size=16×1000=16 000。每一个迭代过程,所有的训练数据集都将通过网络训练一次。在solover.prototxt中,迭代的最大次数为max_iteration=50 000,因此epoch=50 000/1 000=50。当初始学习率base_lr=0.01时,训练中loss值不会下降,甚至在一定的值停止,通过调整base_lr参数来解决这个问题。在本实验中,将base_lr设置为0.001,lr_policy设置为step,Gamma=γ=0.1,stepsize=20 000。根据Step学习策略,学习速率的衰减时间与step有关,衰减程度与“γ”有关。例如,当设置step=500,base_lr=0.0001,Gamma=0.1时,达到第一次500迭代次数时,学习率将开始衰减。衰减后的学习率为a=a×γ=0.000 1×0.1=10-5。即step表示学习速率的衰减步长,“γ”表示衰减因子。优化后的网络训练参数见表1。
| 图表编号 | XD0068617500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.25 |
| 作者 | 耿梦雅、张国平、徐洪波、张莹莹 |
| 绘制单位 | 华中师范大学物理科学与技术学院、华中师范大学物理科学与技术学院、华中师范大学物理科学与技术学院、华中师范大学物理科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}