《表2 DDQN、IDDDQN方法训练8 000次平均奖赏值对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
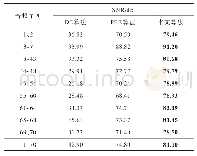
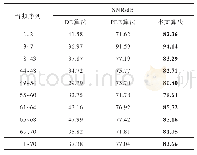
在复杂环境中,从平均累积奖赏值方面对IDDDQN方法和DDQN算法进行比较,结果如表2所示。
| 图表编号 | XD0067434400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 董瑶、葛莹莹、郭鸿湧、董永峰、杨琛 |
| 绘制单位 | 河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室、河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室、河北工业大学人工智能与数据科学学院、河北工程大学、河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室、河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
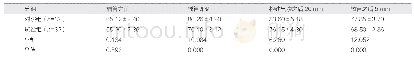


{kind=link}