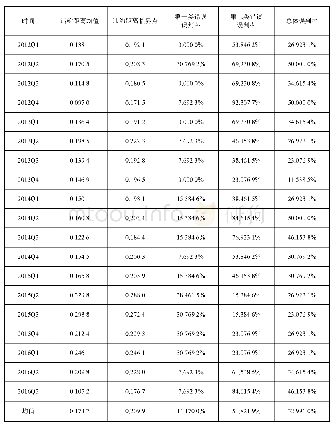
《表7 违约距离的判别效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《我国科技型中小企业风险评价体系研究——基于修正KMV与Logit模型的实证》
为考察犯这两类错误的概率,选择一个违约距离的临界值,若企业的违约距离大于临界值,则被判定为正常企业,反之则被判定为风险企业。由于每一季度企业的违约距离均不相同,故不能对所有季度设定一个统一的临界值作为判定标准。通过查阅相关文献,我们采用50%的当季度样本企业违约距离均值加上50%的2016年第一季度样本企业违约距离均值作为每一季度违约距离的临界值。A组企业中,违约距离大于临界值的企业数量占样本企业总数的百分比即为犯第一类错误的概率,因这部分企业实际属于风险企业,但是却被判定为正常,出现了风险的低估。同理,B组企业中违约距离小于临界值的企业数量占样本企业总数的百分比即为犯第二类错误的概率,因为这部分企业实际属于正常企业,但是却被判定为存在风险,出现了风险的高估。由于违约距离的计算存在误差,所以计算时,给予临界值(-10%,+10%)的上下浮动范围。具体计算结果如表7所示。
| 图表编号 | XD0067304800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 许林、梁婧怡 |
| 绘制单位 | 华南理工大学经济与贸易学院 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}