《表2 基于音频特征的模型性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
C1:组合RF、XGB、MNB和LR
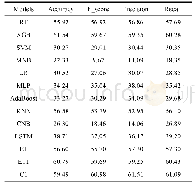
在表2中,基于音频特征的所有单模态模型中,单模态模型XGB的F-score值最高。在使用超参数优化和交叉验证这两种方法后的E11,其F-score值高于先前的E1。四种性能之和最高的组合模型C1,其F-score值(60.98%)高于E1接近9.48%。此外,还可以看到学习模型LSTM(或MLP)的F-score值低于RF、XGB和KNN,更远小于C1。
| 图表编号 | XD006316800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 陈军、王力、徐计 |
| 绘制单位 | 贵州大学大数据与信息工程学院、贵州大学大数据与信息工程学院、贵州工程应用技术学院信息工程学院、贵州工程应用技术学院信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}