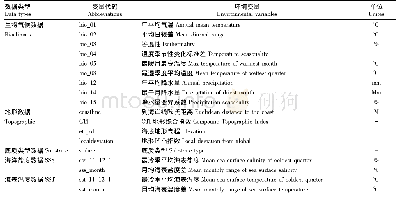
《表1 各CART模型和相应输入变量[36]》
![《表1 各CART模型和相应输入变量[36]》](http://bookimg.mtoou.info/tubiao/gif/GTYG201903003_02400.gif) 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:On b1-7和Off b1-7分别包括生长季和落叶季影像的第1—7波段;On TC和Off TC分别包括生长季和落叶季影像经过缨帽变换后的亮度、绿度、湿度;Light为夜间灯光数据;Slope为坡度;AE为绝对误差;RE为相对误差;R为相关系数。
输入变量的选择和组合是决定模型反演精度和计算效率的关键。选择变量时既需要保证所选波段和光谱指数使不透水面与其他地物的区分度最大,也需兼顾考虑模型计算效率,进行必要数据筛选避免冗余。对输入变量进行组合建立多个机器学习模型,再对比各模型精度和计算时间,选取最优模型是当前的一种普遍方式[12,14]。Hu等[36]利用Landsat TM数据、国防气象卫星线性扫描业务系统(the de-fence meteorological satellite program/operationallinescan system,DMSP/OLS)夜间灯光数据、数字高程模型(digital elevation model,DEM)及其相应的坡度数据,以北京市为研究区,对输入变量进行组合建立了多个CART模型,并进行了模型精度对比分析。各组合模型及其精度分别如表1所示,其结果表明并非输入变量越多反演精度越高,选择对反演贡献较大的变量进行建模可以在保证精度的同时节约计算资源。同样,在类似研究中有学者对不同输入变量和不同机器学习模型开展地物识别的效果进行了对比分析,结果表明在保证输入变量相同的情况下,不同机器学习模型的选择对地物提取精度的差异较小,而合理的选取输入变量则可以使提取精度显著提高[37]。因此,在不透水面比例反演过程中需要结合先验知识和地理特情,选取对地物识别贡献较大的变量建立定量反演模型。
| 图表编号 | XD0061520000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 左家旗、王泽根、边金虎、李爱农、雷光斌、张正健 |
| 绘制单位 | 西南石油大学土木工程与建筑学院、中国科学院水利部成都山地灾害与环境研究所、西南石油大学土木工程与建筑学院、中国科学院水利部成都山地灾害与环境研究所、中国科学院水利部成都山地灾害与环境研究所、中国科学院水利部成都山地灾害与环境研究所、中国科学院水利部成都山地灾害与环境研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}