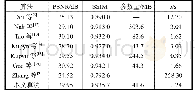
《表1 在合成赣南客家数据集上进行测试结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
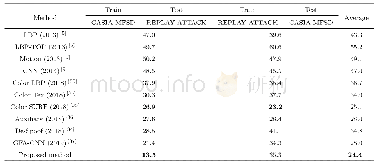
为了验证本文算法在数据量较大时的有效性,以赣南客家群落为研究对象,研究其迁徙地属性特征对迁徙后群落形成的影响,并进一步探讨群落分类。由于客家数据目前仍在整理阶段,因此本文模仿LFR合成数据,主要用于测试不同社区节点数目不同以及节点度数差异较大的网络结构问题。数据生成器允许指定节点数目、平均度数、社区大小分布、度分布、最小最大社区大小、重叠比率。LFR中社区大小和度分布都服从幂率分布,通过抽样的方式生成节点和社区。本节实验中,节点数目设置为201 8,社区数目为13,平均度为10,节点度和社区大小的幂指数分别为-2和-1,重叠比率为0.1~0.5,并将平衡参数设置为1。表1中给出了本文算法在赣南客家网络上的实验结果,由于运行时间较高,因此最终结果取10次实验的平均值。数据集生成时模拟Facebook引入属性,分别是赣南水系(空间:长度、流向、落差,特征:江、河、湖)、赣南地形(面积,特征:丘陵、山地)、耕地(山地、平原)、道路(村、省、国道)等14个特征属性,属性根据生成数据时的聚类或分类分别加入,属性加入服从常见高斯分布,数据生成时间为东晋南北朝末第一次大迁徙到唐末中期第二次大迁徙阶段。
| 图表编号 | XD0058565100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.01 |
| 作者 | 丁彩英、李泽鹏、刘松华 |
| 绘制单位 | 太原理工大学信息与计算机学院、兰州大学信息科学与工程学院、北京大学信息科学与技术学院、太原理工大学信息与计算机学院、北京大学信息科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}