《表3 在WebQuestions数据集上的B组实验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
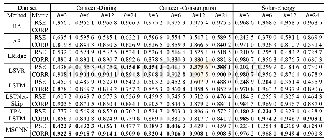
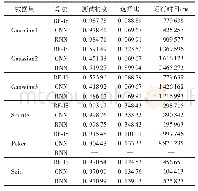
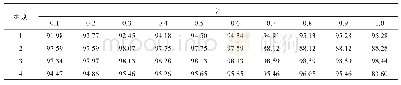
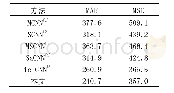
为了验证获取核心词典的作用,我们对比了不获取核心词典而直接使用整个新词典的系统和使用获取到的核心词典的系统。我们都在开发集上进行测试,实验中都使用lemmaAndBinary特征模板,关闭桥连接功能,此外我们还在原始词典的基础上测试了获取核心词典的效果,在两个数据集上的结果如表3和表4所示。从结果中我们可以看到,基于投票机制的核心词典获取方法可以提高系统的准确率,虽然会牺牲一点召回率,但是对系统整体性能起到提高的作用。另外我们还发现获取核心词典的方法能够大大压缩词典的大小。系统所利用的核心词汇是很少的,只占用了原始词汇的1/500不到(在WebQuestions数据集,原始词汇中类别词汇和关系词汇的数量分别是282 005和132 111,而核心词汇的数量分别是66和335)。在后面的实验中,我们都在系统中使用基于投票机制的核心词典获取方法。
| 图表编号 | XD0054899000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 陈波、孙乐、韩先培 |
| 绘制单位 | 中国科学院软件研究所中文信息处理实验室、中国科学院软件研究所中文信息处理实验室、中国科学院软件研究所中文信息处理实验室 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}