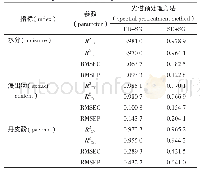
《表2 非定量的变量值处理方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于粒子群算法和BP神经网络的多因素林火等级预测模型》
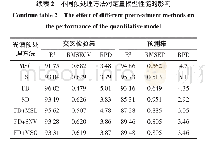
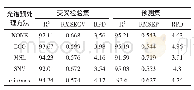
对于所选取的16个变量,如果是定量指标,采用公式(1)或(2)计算;如果是定性指标,则借鉴层次分析法(Saaty[22]的1~9评价方法),首先定性描述其火灾风险,然后将其转化为定量值。定性指标变量值的处理方法如表2所示。根据下蜀林场的植被分布特征,按火灾发生风险由大到小顺序,将植被类型分为4类:杂草、灌木林、混交林、人工林。对于坡向而言,由于阳坡光线好,地被物更易干燥,加大火灾风险;而迎风会带来水汽,降低火灾风险。因此,本研究按火灾发生风险大小顺序,将坡向分为阳坡(背风)、阳坡(迎风)、阴坡(背风)、阴坡(迎风)4种坡向。根据火灾发生风险的大小将以上4种植被类型和坡向定性为:火灾发生风险极大、火灾发生风险较大、火灾发生风险一般、火灾发生风险较小。上述4种定性对应的定量值分别为4,3,2,1。得到定量值后,使用公式(1)将相应的变量值归一化。
| 图表编号 | XD0054564500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.25 |
| 作者 | 王磊、郝若颖、刘玮、温作民 |
| 绘制单位 | 南京林业大学经济管理学院、南京林业大学经济管理学院、南京林业大学经济管理学院、南京林业大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}