《表1 深度强化学习的主要算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在基于策略的强化学习中,最常用的是策略梯度算法。Lillicrap等人将策略梯度方法引入深度强化学习中,提出深度确定性策略梯度[26](Deep Deterministic Policy Gradient,DDPG)算法。DDPG是深度强化学习应用于连续控制强化学习领域的一种重要算法,可以有效解决生成式对抗网络与强化学习结合在模仿学习等方面的机器控制问题。Heess等人提出的分布式近似策略优化算法[27-28](Distributed Proximal Policy Optimization,DPPO)是信赖域策略优化算法(Trust Region Policy Optimization,TRPO)的改良版本,引入了旧策略与更新策略所预测的概率分布之间的KL(Kullback-Leibler Divergence)差异,并据此来控制参数更新的过程,是一种通用的优化思想,本文4.3节就是通过此算法不断优化策略、改进模型。此外,Zhang[29]、Duan[30]、Balduzzi[31]、Heess[32]等也针对策略梯度方法在深度强化学习中的应用进行了研究,并取得了一定的成果。表1列出了深度强化学习的主要算法及其适用领域。
| 图表编号 | XD0053250000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.15 |
| 作者 | 吴宏杰、戴大东、傅启明、陈建平、陆卫忠 |
| 绘制单位 | 苏州科技大学电子与信息工程学院、苏州大学江苏省计算机信息处理技术重点实验室、苏州科技大学电子与信息工程学院、苏州科技大学电子与信息工程学院、苏州科技大学江苏省建筑智慧节能重点实验室、苏州市移动网络技术与应用重点实验室、苏州科技大学电子与信息工程学院、苏州科技大学江苏省建筑智慧节能重点实验室、苏州市移动网络技术与应用重点实验室、苏州科技大学电子与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
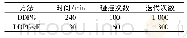





{kind=link}