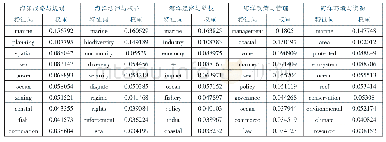
《表2 主题top10特征词及占主题权重》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本试验LDA主题模型使用的Gibbs抽样,设置迭代次数为1000次,超参数取固定的经验值。用word2vec训练文档集时,各参数设置情况为size=100,window=5,min-count=1,cbow=1。其中size代表词向量的维数,window代表上下文窗口大小,mincount代表词语出现的最小阈值,cbow代表是否使用模型CBOW,0为使用,1为不使用。本实验使用Skip-gram模型。LDA和word2vec都是用Gensim实现的,Gensim是用于构建主题模型的免费Python包。对五个主题收集英文语料进行LDA主题建模,得到五个主题的top10特征词及占主题权重(见表2)。
| 图表编号 | XD0052167500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 刘艳民、张旺强、祝忠明、陈宏东 |
| 绘制单位 | 兰州大学图书馆、中国科学院兰州文献情报中心、中国科学院兰州文献情报中心、兰州大学图书馆 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}