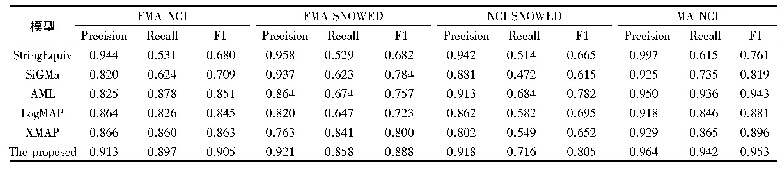
《表1 两种不同的语音对齐》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
2基于概率理论的关系词识别方法。相对于基于语音相似性的方法而言,基于概率理论的识别方法更为客观,理据性更强,所得到的结论也更为可靠。但是由于目前主要的关系词自动识别程序都是针对多音节语素语言的,多音节语素语言关系词识别中的语音对齐问题上的困难使得基于概率的方法未得到广泛应用。相对而言,汉藏语系诸语言在概率方法的应用上则具有独特的优势:同印欧语等多音节语言不同,汉藏语语素的音节结构多是单音节的,一个音节可以清晰的切分为声、韵、调等几个部分,对当音节之间也可以依据声、韵、调实现严整的对齐。因此,汉藏语语言进行关系词识别时,音节内的语音对齐问题是不存在的(1)。当然,汉藏语的关系词识别问题中也并非不存在语音对齐问题,而是同印欧语等多音节语素语言相比,语音对齐的层面不一样:由于语音的插入、丢失等语音演变方式的存在及单词内部音节界限的模糊性等原因,多音节语素语言的语音对齐需要在音素层面进行;而汉藏语单词中音节界限清晰,音节内部结构也非常固定,其语音对齐主要是在音节层面进行的。如在进行意大利语和拉丁语单词“穿”的语音对齐时,对齐工作是在整个词的层面以音素为单位进行的,而在对藏语的两种方言中的“耳朵”一词进行对齐时,只需要将音节对齐即可,由于音节结构确定,音节内部的对齐是不言自明的(2)(见表1)。因此,在藏缅语研究中,完成音节对齐之后就可以直接根据各音节声韵调的对应情况计算音节对应的概率了(陈保亚1996:216-228)。此外,在多音节词汇中,还需要解决词根语素的鉴别问题,只有词根语素对应的词对才能确定为关系词。由于词根语素的鉴别涉及复杂且相对模糊的语义分析问题,并不适合于使用计算机处理,因此多音节关系词的最终确定仍需要人工检验和分析。从这一点来看,在历史语言学研究中,计算机技术仍只适合作为一种辅助工具,它终究无法代替学者进行真正的研究工作。
| 图表编号 | XD0046725300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 高天俊 |
| 绘制单位 | 华中科技大学中文系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}