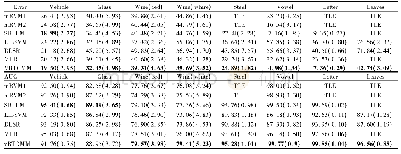
《表3 VBTGMM和6个对比算法在8个公开数据集上的45次随机划分实验的错误率和AUC值的平均值 (标准差)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表3是45次实验的错误率和AUC值的平均值(和标准差).一些算法在一些数据集上无法在可容忍时间内运行出结果,我们用(Time Limit Exceeded,TLE)标记.8个数据集是以类别数排序,类别数从左至右逐渐增大.可以看出,当类别数较小时(比如4或6),各种算法区别不大.但当类别数增大时,VBTGMM在错误率和AUC两个指标下均有优秀表现.注意到同为基于贝叶斯的算法,mRVM1和mRVM2在训练集变大时,便无法在可接受的时间内运行结束.而正如之前的理论分析,由于VBTGMM将矩阵求逆时基样本数从降至平均的,拥有相对较小的时间消耗.值得一提的是,当数据集的类别数达到100时,4个对比算法都无法在合理时间内运行出结果,而剩下2个对比算法在也错误率和AUC上,与VBT-GM M相差甚远.能在100类这种大类别上达到一个比较理想的结果,得益于在TGMM中,权重在初始时是一个的向量.而同类算法的权重是一个会随类别数增加而增加的矩阵.更多的权重带来的过拟合导致它们在测试集上的表现不佳.
| 图表编号 | XD0045019700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 田星、陈欢欢 |
| 绘制单位 | 中国科学技术大学计算机科学与技术学院、中国科学技术大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}