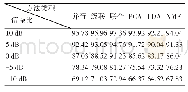
《表2 不同算法在高斯噪声下的平均识别率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
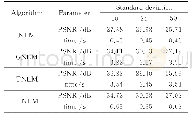
从表3可以看出,运算效率方面SVM最优,其次为CNN,因其CNN是一种深层的神经网络,而SVM是一种两层的浅层网络结构,且CNN的输入特征(32×32=1 024维)明显要高于SVM的输入特征(512维)。相比之下,隐马尔可夫模型和贝叶斯分类器显得很慢,隐马尔可夫需要为每一个汉字建立几个HHM模型,不同状态个数的模型并不能共享同一个算法;而贝叶斯分类器在提取汉字特征时需要进行较多的参数以提高其识别概率,并且它们随着训练样本的增加变得更慢。其中SVM和CNN都在合理的时间范围内。在存储量上,线性SVM的参数主要由特征维数和类别数决定(512×10=5 120),相比之下CNN存储量更低,有明显的优势。
| 图表编号 | XD003922100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 任晓文、王涛、李健宇、赵祥宁、郭一娜 |
| 绘制单位 | 太原科技大学电子与信息工程学院、太原科技大学电子与信息工程学院、太原科技大学电子与信息工程学院、太原科技大学电子与信息工程学院、太原科技大学电子与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}