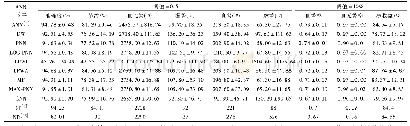
《表2 第一个MapReduce的输出情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《Spark框架下利用分布式NBC的大数据文本分类方法》
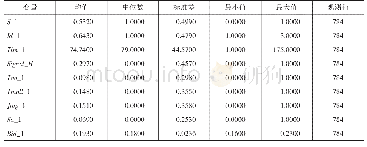
其中三个MapReduce的输出情况如表2~4所示。表中的label指类标签即Cj,token是特征词,即wk。第一个MapReduce统计训练集中出现wk的次数,计算每类中每个特征词的词频(TF)值;第二个MapReduce根据第一个MapReduce的输出文件计算每个特征词的词频逆向文件频率(TF-IDF)值。待计算完毕后,将自动删除第一个MapReduce得出的featureCount、word Frep、term Doc Count三个文件。第三个MapReduce按照公式:∑log[(TFIDF+1.0)/π(sigma-k+Vocab Count)]对表3的两个文件进行计算,并输出结果。在之前的计算基础之上,最后mapper的返回值是测试文档则属于Cj类,与在其他类下的值进行比较,取出最大值所属的类标签值。
| 图表编号 | XD003906800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 臧艳辉、赵雪章、席运江 |
| 绘制单位 | 佛山职业技术学院、佛山职业技术学院、华南理工大学 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}