《表2 数据集:基于语义分布相似度的主题模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
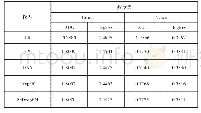
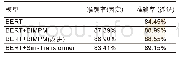
本实验是在单机多核服务器上进行的,该服务器由两个IntelXeon[email protected] GHz的CPU组成,每个CPU有8个内核,总计16核心,140 GB内存。本文实验是在四个公开数据集上进行,分别为Cora、Web KB、Reuters R8(R8)和20 Newsgroups(20 News)数据集,文献[18]对其进行了相关的介绍,表2展示了这四个数据集的相关信息描述。
| 图表编号 | XD003886600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 居亚亚、杨璐、严建峰 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



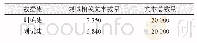
{kind=link}