《表1 实验样本:改进的K-means聚类k值选择算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
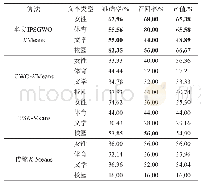
如表1,Iris数据集合包含150个数据对象,任一对象包含4个属性,包含3种不同的类别标签,每个标签对应50个样本对象[18];dataR2数据集合包含117个数据对象,任一对象包含9个属性,包含2种不同标签,分别对应52、65个数据对象;wine数据集包含对象178个,3类别标签分别对应59、71和48个样本对象;Immunotherapy数据集包含90个数据对象,每个数据对象包含7个属性,共2类,分别对应19、71个数据对象。选择传统的“手肘法”与本文基于“手肘法”提出的改进算法ET-SSE算法,将其分别应用于具有不同标签数量、不同样本量的dataR2、Iris、Wine和Immunotherapy数据集,测试改进算法的实际运行效果是否优于SSE;并将该改进算法与常用的“事后”判断k值是否最优的算法SSE和轮廓系数法就算法的运行时间、k值选择的准确率两个方面进行对比测试,以说明本文提出的改进算法的有效性。
| 图表编号 | XD0035460400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.15 |
| 作者 | 王建仁、马鑫、段刚龙 |
| 绘制单位 | 西安理工大学经济与管理学院、西安理工大学经济与管理学院、西安理工大学经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |

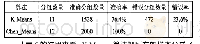



{kind=link}