《表2 文本数据长度:基于多输出神经网络的舆情分析指标拟合及优化研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
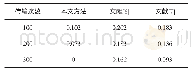
在预处理过程中,首先采用jieba中文分词工具对中文文本进行分词[20],并去除文本中的数字与标点符号,并将它们索引化表示;然后综合索引化表示结果与预训练词向量的前200 000个词语,完成深度学习的特征表示。实验中,使用的分词长度均为文本分词结果长度的平均值加减2倍方差。文本数据长度,如表2所示。
| 图表编号 | XD0031685700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 陈娟、王功明、徐翼龙、王海威 |
| 绘制单位 | 北京大学新闻传播学院、中国科学院生物物理研究所、北京联合大学智慧城市学院、军委后勤保障部信息中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}