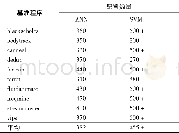
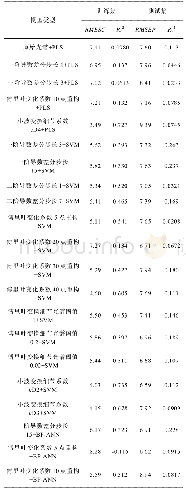
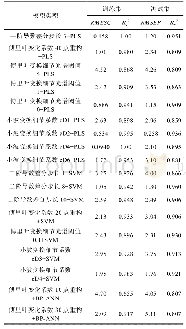
《表2 为达到SSLBoost模型相同的预测精度, ANN和SVM所需要的模拟配置 (训练样本) 数量Table 2 Numbers of simulated configurations (trai
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
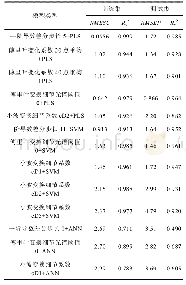
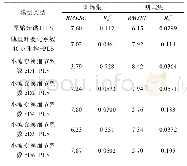
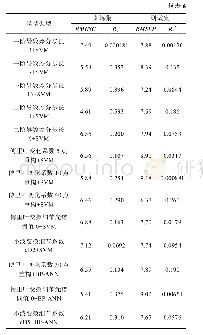
从表2可以看出,ANN和SVM分别需要191%、228+%的模拟样本,才能达到和SSLBoost模型相当的预测精度。“+”表示对于一些基准程序,ANN或SVM用尽了所有备用训练样本(300),还是不能达到SSLBoost模型的预测精度。总之,SSLBoost模型能够节省大量的训练模拟。
| 图表编号 | XD002671200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.04.01 |
| 作者 | 李丹丹、姚淑珍、王颖、王森章、谭火彬 |
| 绘制单位 | 北京航空航天大学计算机学院、北京航空航天大学计算机学院、中国科学院计算技术研究所计算机体系结构国家重点实验室、南京航空航天大学计算机科学与技术学院、北京航空航天大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}