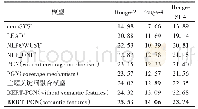
《表1 实现结果:中文文本敏感信息自动校对方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于涉及语义方面的敏感信息,较为复杂,不能通过规则来实现,所以本文未对其进行处理;而且,人工核对部分可能存在少量误差。排除这些原因,由表1的结果可以看出,本实验的召回率、准确率和F值是很突出的,而且,为了减少漏报,开始写的规则比较宽泛、适应面广,然后通过大量的数据进行验证、统计和分析每个规则的误报情况,再进行规则的修改,并加入情感分析的方法减少误报。本方法在排除某些无法验证的敏感信息外,在保证召回率的情况下,通过人工审核完善规则不断提升准确率,效果非常明显,适合当下内容安全中的敏感信息自动校对,已经在实际环境中应用,帮助相关的职能部门及早发现一些敏感信息,并尽早处理,以免造成严重的影响。
| 图表编号 | XD0023138900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.12.10 |
| 作者 | 龚永罡、汪昕宇、李玉莹、王蕴琪 |
| 绘制单位 | 北京工商大学计算机与信息工程学院、北京工商大学计算机与信息工程学院、北京工商大学计算机与信息工程学院、北京工商大学计算机与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}