《表4 各预测算法的事故与非事故预测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
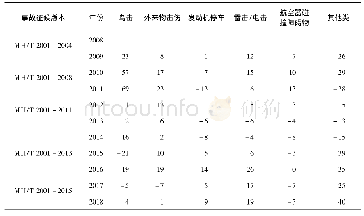
缺失的事故数据填补前,用于训练和测试预测算法数据一共106组,其中事故数据35组,非事故数据71组,非事故数据的数据量是事故数据量的2倍,机器学习算法,其预测结果更偏向于数据量多的那一类[5]。从图6中的结果可知:KNN受数据不平衡影响明显大于SVM算法,在事故数据少的情况下,事故数据被准确预测的概率为70.40%,远低于其87.95%的平均预测准确度,2种算法的事故与非事故测试结果见表4,其中,“P”为预测数据集中事故数据组数,“PN”为事故数据预测成非事故数据的平均组数,“N”为预测数据集中非事故数据组数,“NP”为非事故数据预测成事故数据的平均组数。
| 图表编号 | XD00215617100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 郑晓亮##教授、来文豪、薛生##教授 |
| 绘制单位 | 安徽理工大学深部煤矿采动响应与灾害防控国家重点实验室、安徽理工大学电气与信息工程学院、安徽理工大学电气与信息工程学院、安徽理工大学深部煤矿采动响应与灾害防控国家重点实验室、安徽理工大学能源与安全学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}