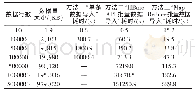
《表1 HBase数据导入性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于HBase的小集群风电SCADA系统高效数据存取算法研究》
上述3种HBase数据导入方法的测试结果对比如表1所示,逐步增加导入数据的规模并记录实际消耗时间。因为HBase自带的数据导入算法都是单线程实现,所以无论是方法一还是方法二都无法满足高性能数据导入要求,而且会出现CPU负载高,HMaster服务崩溃(如表1中,“-”代表服务崩溃)。方法三由于是采用多线程实现,其性能显然优于前两种方式。但是,通过进一步对小集群研究发现,Map Reduce其自启动需要消耗一定的基础资源,且其性能优劣与集群规模大小呈正相关,对于数据量到达千万级及以上大小的大集群才能发挥比较好的性能表现,而小集群数据规模通常保持在500万以下,因而,小集群规模环境下其性能优势并不明显。因此,小集群想要获得更高效的数据导入,并不能直接采用方法三“Map Reduce批量导入”,而需要设计一种新的算法,本文考虑对方法二“HBase API批量数据导入”进行算法改进。新算法的设计目标是性能超越现有3种主流HBase数据导入方法中最好的方法三。
| 图表编号 | XD00214873400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 陈敏、汤晓安、刘行、谢鑫 |
| 绘制单位 | 湖南信息学院电子信息学院、国防科技大学电子科学学院、长沙北斗产业安全技术研究院、湖南信息学院电子信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}